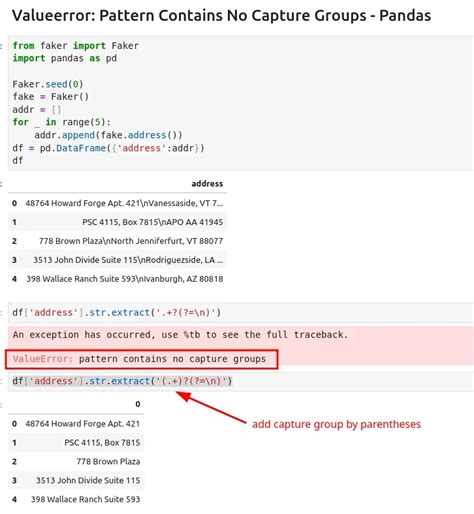
When using regular expression, I get:
import re string = r' result = re.search('^.*com', string).group() In pandas, I write:
df = pd.DataFrame(columns = ['index', 'url']) df.loc[len(df), :] = [1, ' df.loc[len(df), :] = [2, ' df.str.extract('^.*com') ValueError: pattern contains no capture groups How to solve the problem?
Thanks.
03 Answers
According to the docs, you need to specify a capture group (i.e., parentheses) for str.extract to, well, extract.
Series.str.extract(pat, flags=0, expand=True)
For each subject string in the Series, extract groups from the first match of regular expression pat.
Each capture group constitutes its own column in the output.
df.url.str.extract(r'(.*.com)') 0 0 1 # If you need named capture groups, df.url.str.extract(r'(?P<URL>.*.com)') URL 0 1 Or, if you need a Series,
df.url.str.extract(r'(.*.com)', expand=False) 0 1 Name: url, dtype: object You need specify column url with () for match groups:
df['new'] = df['url'].str.extract(r'(^.*com)') print (df) index url new 0 1 1 2 Try this python library, works well for this purpose:
Using urllib.parse
from urllib.parse import urlparse df['domain']=df.url.apply(lambda x:urlparse(x).netloc) print(df) index url domain 0 1 1 2 ncG1vNJzZmirpJawrLvVnqmfpJ%2Bse6S7zGiorp2jqbawutJobG1rZGiAeISOqZinnJGoerety66cnqqipL9uvMCtq56qnmKwsLrTmqCnq12jvG6vwKmrrqqVYrSzu9Spqg%3D%3D